
Table of Contents
- Running the LIWC Analysis
- Interpreting the LIWC Output
- Introductory References for Understanding LIWC
- Understanding the LIWC Summary Measures
Running the LIWC Analysis
In previous versions of LIWC, the "LIWC Analysis" was the heart and brains of the entire application. The same is true today, and most of what LIWC-22 is designed to do is to either analyze texts for psychologically meaningful categories of language, or perform related analyses to help you better understand your language data. In LIWC-22, the "traditional" analysis performed by LIWC can be found by the "Home" icon labeled "LIWC Analysis."
We have worked to ensure that performing the core type of analysis that LIWC users know and love is just as easy as ever (and, in many ways, easier). LIWC-22 is able to read texts contained in separate .txt, MS Word, or PDF files and analyze them for psychological categories of language. Similarly, if you have all of your texts in a single spreadsheet (CSV or MS Excel), the same analysis can be performed quickly and easily.
To get started, LIWC-22 will ask you to import your dataset in one of the above-described formats:
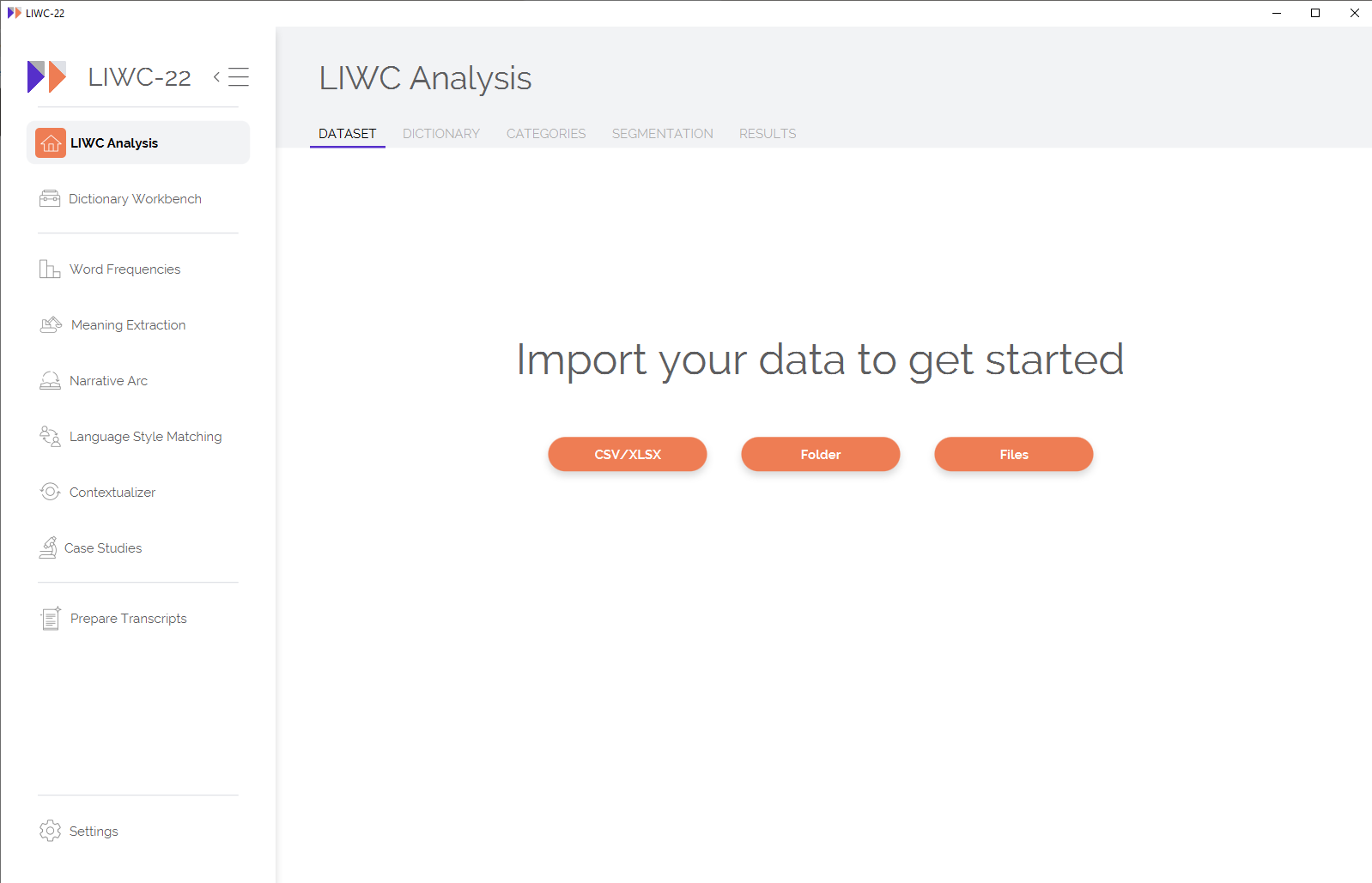
If analyzing data within a spreadsheet, LIWC-22 will show you a preview of your dataset and ask you to indicate which column(s) you want to analyze as text. You can choose to analyze each column of text separately by checking the "Treat Each Cell as a Separate Text" option. Otherwise, LIWC will aggregate the text columns within each row for analysis. By default, the first row is considered to be a "header" row that contains variable names, etc. You can undo this by unchecking the "Use first row as a header" box on the top right corner.
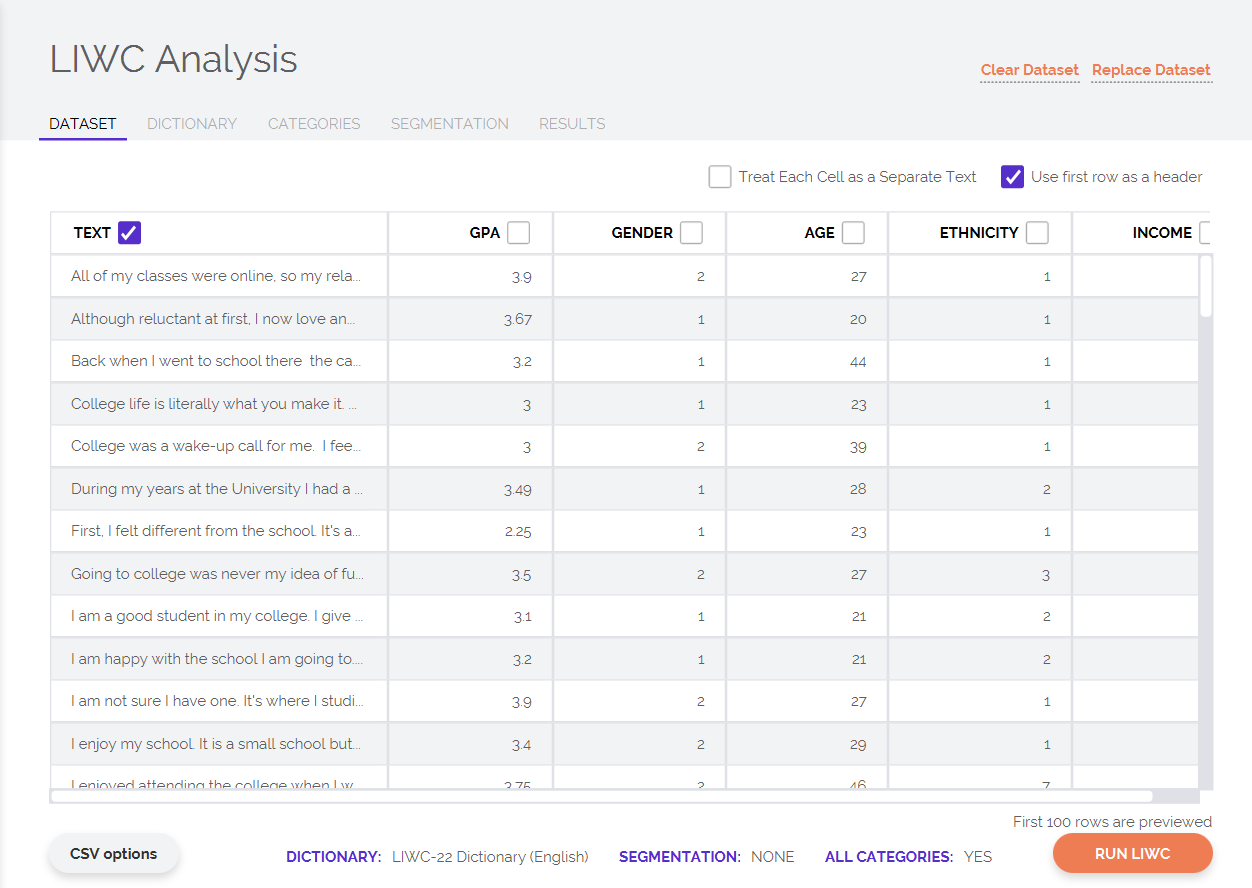
At the bottom of the page, you should see LIWC’s current settings– the current dictionary, categories, and segmentation settings. You can change the settings by clicking on the relevant setting or by navigating to the relevant tab.
- On the Dictionary tab, you will see a list of LIWC’s internal dictionaries as well as any external dictionaries that you have previously used. You can select which dictionary you would like to use to analyze your dataset. Alternatively, you can load an external dictionary file from your computer, which can be in either the "old" LIWC dictionary format (.dic) or the newer LIWC-22 dictionary format (.dicx). You can also browse through dictionaries that other scholars have created by clicking on the Get More Dictionaries button (valid for academic users only).
- The Categories tab lists all of the categories contained within your selected dictionary. On this tab, you can choose to enable/disable various categories of interest. Note that not all LIWC-22 dimensions are available when using a custom dictionary; for example, calculation of the "Analytic Thinking" summary measure relies on LIWC-22's internal dictionaries and cannot be calculated when using a custom dictionary file.
- The Segmentation tab allows you to specify whether you want your text(s) to be segmented or chunked before being analyzed. There are a number of segmentation options: you can choose to split all of your texts into a predefined number of segments, split all texts into segments of approximately N number of words, or segment by special characters or number of carriage returns. Note that if you are segmenting extremely large texts (e.g., a single text file with hundreds of millions of words), processing can take an extended period of time.
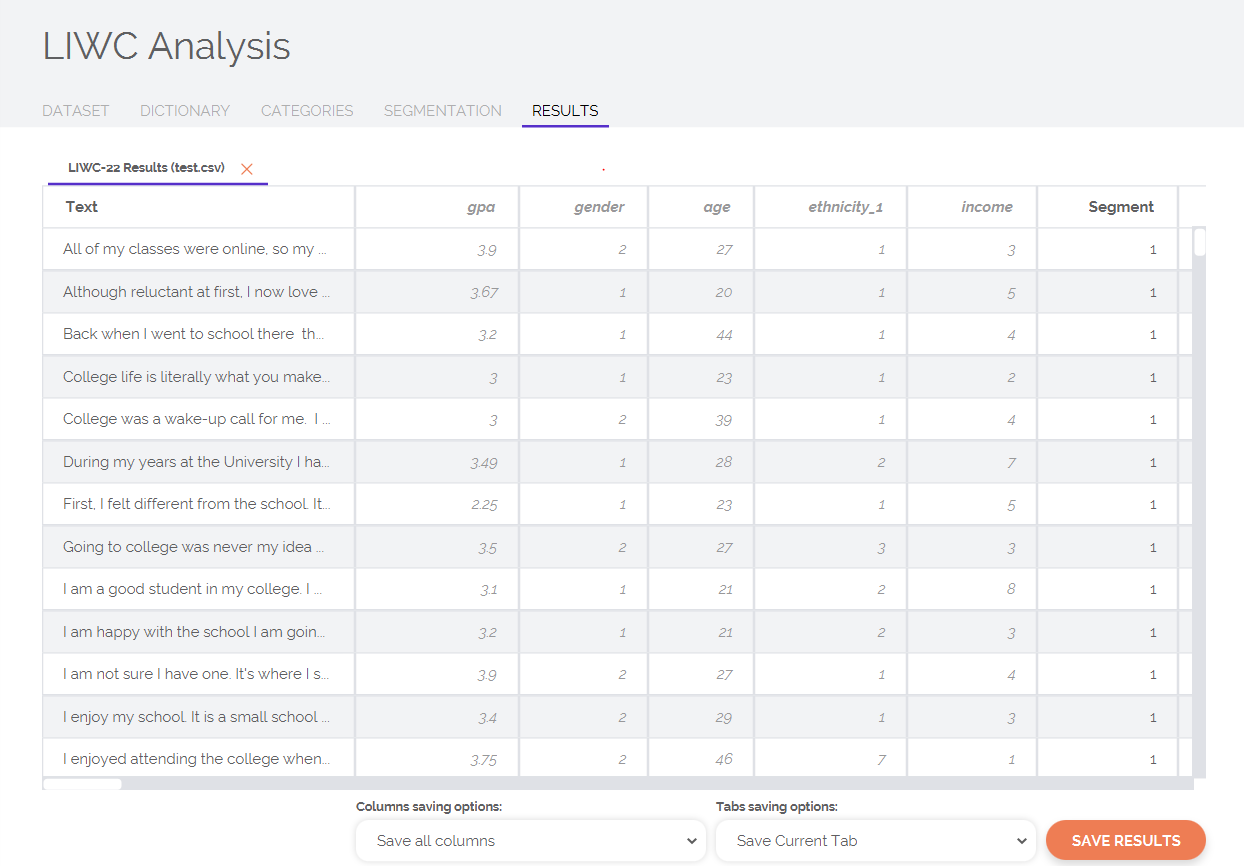
Clicking the Run LIWC button will analyze your texts; when processing is finished, you will automatically be directed to a tab containing your results. On the Results page, you can save either a specific set of results or, if you have run several sets of analyses, you can export the results from all of your tabs at once. If you analyzed data in a CSV or Excel spreadsheet, you can also select which of the original dataset's columns you would like to retain/carry over into your LIWC output file. By default, LIWC saves all columns. If your dataset is too large, you may want to save the file without the text or only the LIWC output. If you don’t save all the columns, make sure to save an ID column in case you want to match the LIWC output with the text later.
Interpreting the LIWC Output
There are many ways to think about the LIWC output — both linguistically and statistically, but also psychologically. Here are some helpful guidelines.
Where do the numbers come from? How are they calculated?
Most of the LIWC output variables are percentages of total words within a text. For example, imagine you have analyzed a blog and discover that the Positive Emotions (emo_pos) number was 4.20. That means that 4.20 percent of all the words in the blog were positive emotion words.
A few LIWC variables are calculated differently from the others: word count (WC), words per sentence (WPS), and the summary measures. WC is the raw number of words within a file. WPS is the mean number of words within each sentence within the file.
Okay, but what do These Numbers Mean? Like, Psychologically?
Most of the LIWC-22 variables are reasonably straight-forward. For example, personal pronouns simply refer to the percentage words in a given text that are personal pronouns. The psychological meaning of the use of personal pronouns is less clear, however. Indeed, careers have been built on trying to understand what different categories of verbal behavior tell us about a person's mental states, personality, and broader psychological universe.
If you're looking for a good place to start learning about the psychological meaning of words, and LIWC dimensions in particular, check out "The Psychological Meaning of Words" by Tausczik and Pennebaker (2010) and The Secret Life of Pronouns book by Pennebaker (2011). We also strongly encourage you to go to Google Scholar and enter search terms such as “LIWC and pronouns” or “LIWC and depression” or “LIWC” together with whatever dimension or psychological construct you are interested in. There are thousands of articles published using LIWC — there is bound to be published research related to your own interests.
Introductory References for Understanding LIWC
Over the years, several places have discussed how LIWC works, as well as how one can begin to appreciate the psychology behind the words that people use in everyday life. If you'd like to learn more about LIWC in general, as well as the theory and research behind LIWC, you might consider reading the "How It Works" page on this site, as well as any of the following publications:
- Boyd, R. L. (2017). Psychological text analysis in the digital humanities. In S. Hai-Jew (Ed.), Data Analytics in Digital Humanities (pp. 161–189). Springer International Publishing. https://doi.org/10.1007/978-3-319-54499-1_7
- Pennebaker, J. W. (2011). The secret life of pronouns: What our words say about us. Bloomsbury.
- Tausczik, Y. R., & Pennebaker, J. W. (2010). The psychological meaning of words: LIWC and computerized text analysis methods. Journal of Language and Social Psychology, 29(1), 24–54. https://doi.org/10.1177/0261927X09351676
Understanding the LIWC Summary Measures
LIWC-22 contains four summary measures: Analytical Thinking, Clout, Authenticity, and Emotional Tone. Each of the summary measures are algorithms derived from various LIWC variables based on previous empirical research. The numbers are standardized scores that have been converted to percentiles (based on the area under a normal curve) ranging from 1 to 99. Although the algorithms are proprietary, you can compute them by going to the research articles on which they are based. A brief overview of each summary variable follows.
A note about Summary Measures. Summary Measures depend on the presence of a certain amount of information within a text to yield meaningful results. Consequently, you may find that several summary measures are not computed for a given text if it lacks the necessary information. For instance, consider a text containing only the word "Stop." Such minimal data does not contain enough content to determine its level of analytic thinking or authenticity. In such cases, LIWC-22 considers this data as missing rather than providing an inaccurate score that is essentially meaningless. This typically occurs with very short texts — the more extensive the language data available for analysis, the higher the likelihood that all four summary measures will be able to be computed accurately.
Analytical Thinking (Analytic)
The analytical thinking variable is a factor-analytically derived dimension based on several categories of function words. Originally published as the Categorical-Dynamic Index, or CDI, Analytic Thinking captures the degree to which people use words that suggest formal, logical, and hierarchical thinking patterns. People low in Analytical Thinking tend to write and think using language that is more intuitive and personal. Language scoring high in Analytic Thinking tends to be rewarded in academic settings and is correlated with things like grades and reasoning skills. Language scoring low in Analytic Thinking tends to be viewed as less cold and rigid, and more friendly and personable.
Some key references to help understand the Analytic Thinking measure include:
- Pennebaker, J. W., Chung, C. K., Frazee, J., Lavergne, G. M., & Beaver, D. I. (2014). When small words foretell academic success: The case of college admissions essays. PLOS ONE, 9(12), e115844. https://doi.org/10.1371/journal.pone.0115844
- Boyd, R. L., & Pennebaker, J. W. (2015). Did Shakespeare write Double Falsehood? Identifying individuals by creating psychological signatures with text analysis. Psychological Science, 26(5), 570–582. https://doi.org/10.1177/0956797614566658
- Jordan, K. N., Sterling, J., Pennebaker, J. W., & Boyd, R. L. (2019). Examining long-term trends in politics and culture through language of political leaders and cultural institutions. Proceedings of the National Academy of Sciences, 201811987. https://doi.org/10.1073/pnas.1811987116
Clout
Clout refers to the relative social status, confidence, or leadership that people display through their writing or talking. The Clout algorithm was developed based on the results from a series of studies where people were interacting with one another (e.g., Kacewiczet al., 2013). Note that Clout is different from the concept of "Power" (including the LIWC-22 "power" variable). Power or, more accurately, the need for power, reflects people’s attention to or awareness of relative status in a social setting. You can have a confident leader who has no interest in other people’s standing in the social hierarchy.
Some key citations for the Clout measure include:
- Kacewicz, E., Pennebaker, J. W., Davis, M., Jeon, M., & Graesser, A. C. (2014). Pronoun use reflects standings in social hierarchies. Journal of Language and Social Psychology, 33(2), 125–143. https://doi.org/10.1177/0261927X13502654
- Drouin, M., Boyd, R. L., Hancock, J. T., & James, A. (2017). Linguistic analysis of chat transcripts from child predator undercover sex stings. The Journal of Forensic Psychiatry & Psychology, 28(4), 437–457. https://doi.org/10.1080/14789949.2017.1291707
- Fox, A. K., & Royne Stafford, M. B. (2021). Olympians on Twitter: A linguistic perspective of the role of authenticity, clout, and expertise in social media advertising. Journal of Current Issues & Research in Advertising, 42(3), 294–309. https://doi.org/10.1080/10641734.2020.1763521
Authenticity
When people reveal themselves in an "authentic" or honest way, they tend to speak more spontaneously and do not self-regulate or filter what they are saying. The algorithm for Authenticity was originally derived from a series of studies where people were induced to be honest or deceptive (Newman et al., 2003) as well as a summary of deception studies published in the years afterwards (Pennebaker, 2011). However, over the years we have come to understand that the Authenticity measure has less to do with "deception" in a traditional sense and is, instead, more a reflection of the degree to which a person is self-monitoring. Examples of texts that score low in Authenticity include prepared texts (i.e., speeches that were written ahead of time) and texts where a person is being socially cautious. Examples of texts that score high in Authenticity tend to be spontaneous conversations between close friends or political leaders with little-to-no social inhibitions.
Some key citations for the Authentic measure include:
- Newman, M. L., Pennebaker, J. W., Berry, D. S., & Richards, J. M. (2003). Lying words: Predicting deception from linguistic styles. Personality and Social Psychology Bulletin, 29(5), 665–675. https://doi.org/10.1177/0146167203029005010
- Kalichman, S. C., & Smyth, J. M. (2021). “And you don’t like, don’t like the way I talk”: Authenticity in the language of Bruce Springsteen. Psychology of Aesthetics, Creativity, and the Arts. https://doi.org/10.1037/aca0000402
- Markowitz, D. M., Kouchaki, M., Gino, F., Hancock, J. T., & Boyd, R. L. (2023). Authentic first impressions relate to interpersonal, social, and entrepreneurial success. Social Psychological and Personality Science, 14(2), 107–116. https://doi.org/10.1177/19485506221086138
Emotional Tone
Although LIWC-22 includes both positive tone and negative tone dimensions, the Tone variable puts the two dimensions into a single summary variable. The algorithm is built so that the higher the number, the more positive the tone. Numbers below 50 suggest a more negative emotional tone.
Some citations for further reading include:
- Cohn, M. A., Mehl, M. R., & Pennebaker, J. W. (2004). Linguistic markers of psychological change surrounding September 11, 2001. Psychological Science, 15(10), 687–693. https://doi.org/10.1111/j.0956-7976.2004.00741.x
- Monzani, D., Vergani, L., Pizzoli, S. F. M., Marton, G., & Pravettoni, G. (2021). Emotional tone, analytical thinking, and somatosensory processes of a sample of Italian tweets during the first phases of the COVID-19 pandemic: Observational study. Journal of Medical Internet Research, 23(10), e29820–e29820. https://doi.org/10.2196/29820