
Understanding and Measuring the Dictionary Workbench
LIWC-22 comes with an entirely new Dictionary Workbench feature that helps you to create and evaluate your own dictionary files. Using the Dictionary Workbench, you can create a dictionary from a blank dictionary, or from a built-in template, or by loading an external dictionary file. Note that the LIWC-22 Dictionary Workbench can read both old LIWC dictionary formats (e.g., LIWC2007 and LIWC2015 dictionaries) as well as the new LIWC-22 dictionary format.
Once you have selected whether you want to create a dictionary from scratch or modify an external dictionary, you will see a table on the LIWC screen. In the table that loads, each row corresponds to a word in the dictionary, and each column corresponds to a category. To add a new word, you need to click on Add Row and type the word you want to add. To add a dictionary, click on Add Column. To add a word to a category, you simply need to click the corresponding cell. For instance, in the below screenshot, you see an "X" next to the word learn underneath school column — this indicates that the word learn is mapped into the category. You can map words to as many categories as you would like.
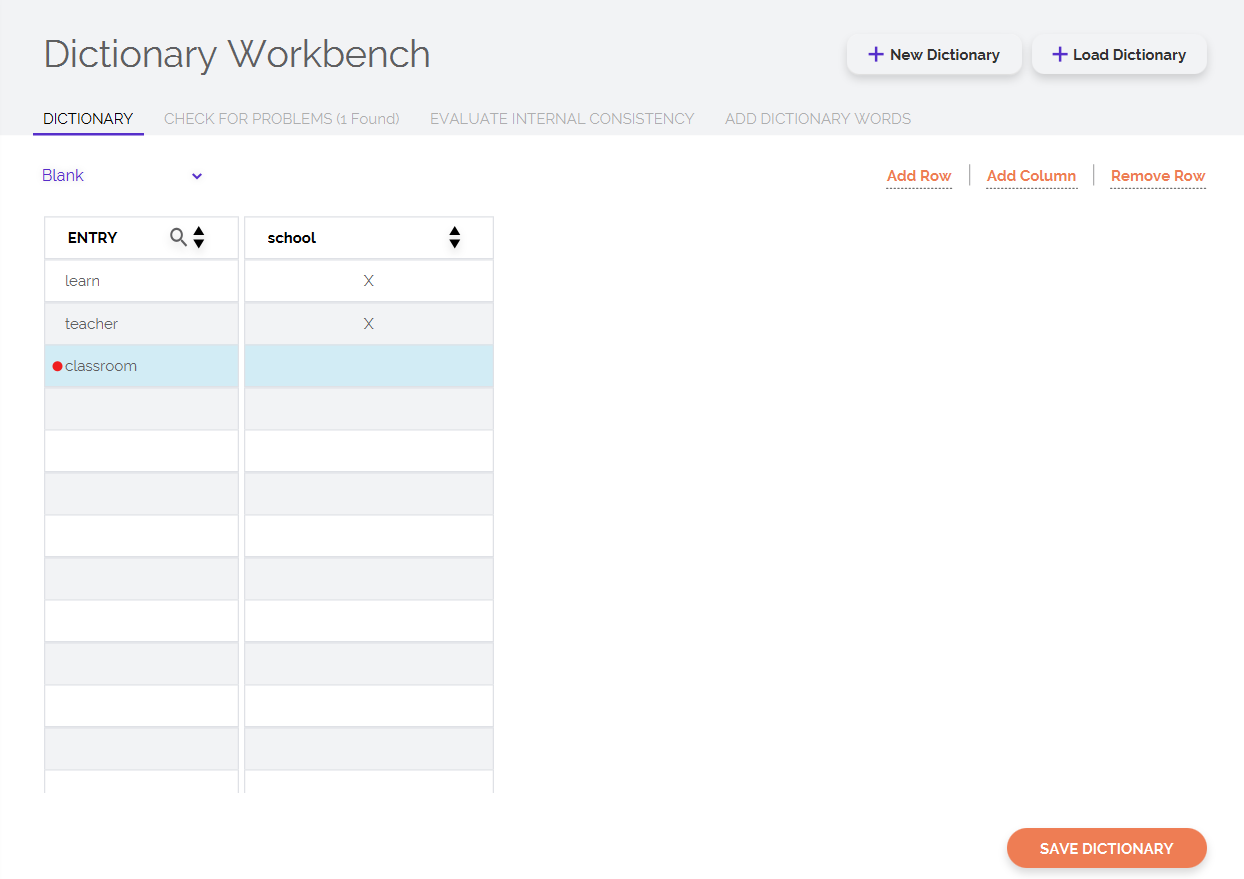
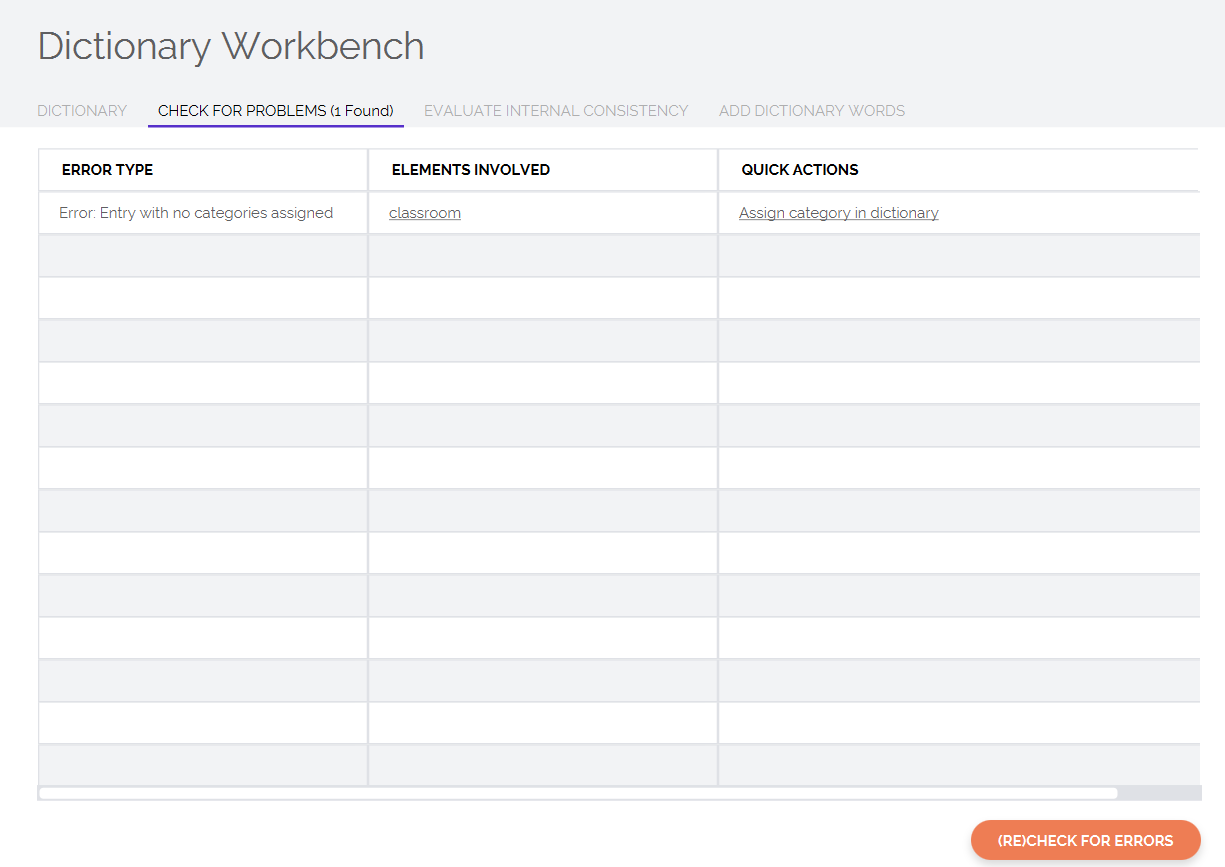
Note that the program automatically flags errors with a red circle. If you hover over the circle, you will see some information about what the error is. The Check For Problems tab provides more details about all strucutral and conceptual problems that the Dictionary Workbench has identified in your dictionary.
Evaluate Internal Consistency
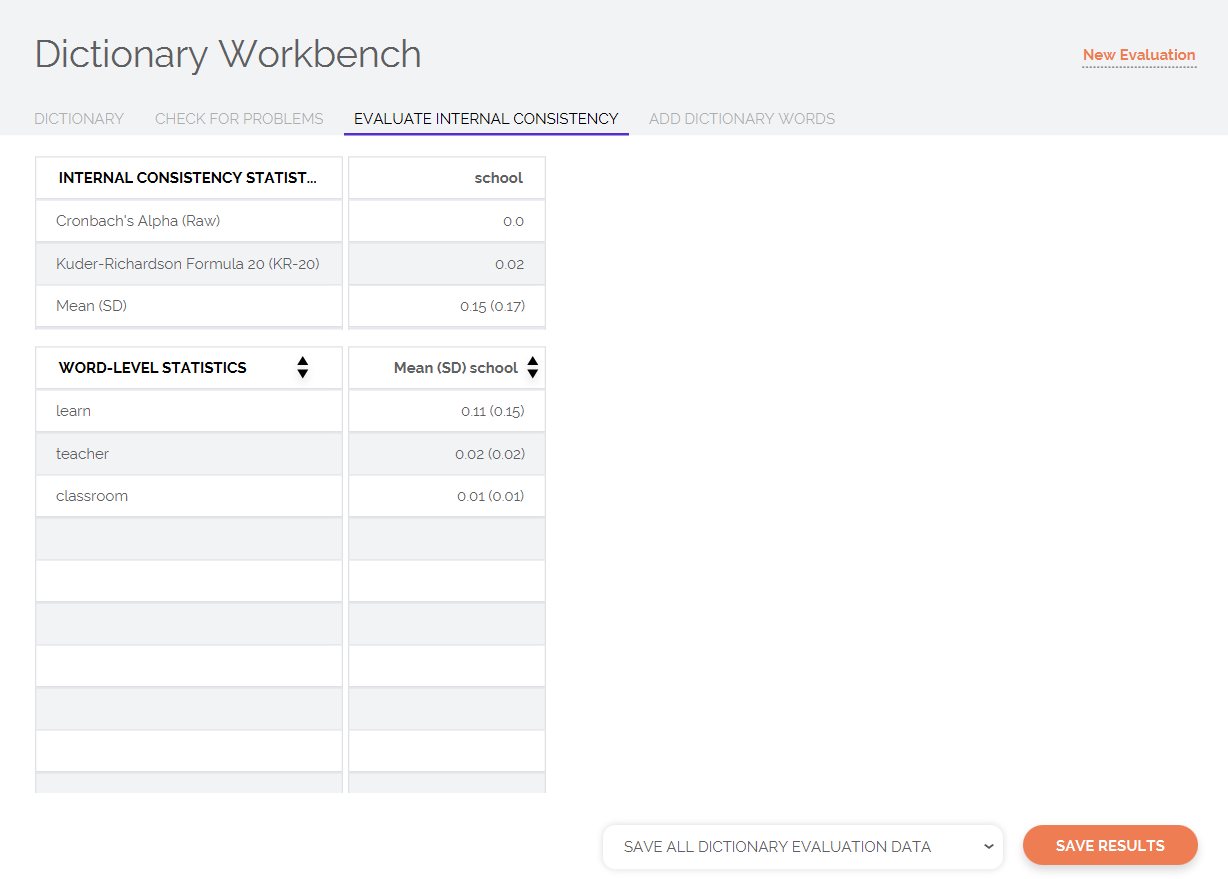
The Evaluate Internal Consistency feature of the Dictionary Workbench can be used to evaluate some of the standard psychometric properties of your dictionary. This process allows you to take a dataset of your choice and calculate two commonly-used internal consistency statistics, including Cronbach’s alpha and KR-20. Briefly described, these two metrics provide a heuristic sense of how well the words in each category reflect a common, unified construct. If the words in a given category are capturing the same concept or closely related concepts, the words should tend to co-occur, resulting in greater intercorrelations and therefore higher internal consistency statistics. Low internal consistency numbers may suggest that the words in your dictionary are not correlated with each other, meaning they do not represent a singular unified construct. You might consider removing words that you think are not directly related to the concept you want to capture and re-evaluating the dictionary.
PROTIP: It is important to note that a high internal consistency statistic does not inherently mean that a dictionary is "good" and, likewise, a low internal consistency statistic does not inherently mean that a dictionary is "bad" or poorly designed. The assessment of psychological processes through verbal behavior is incredibly complex, and classical psychometric theory that is often used for the development of surveys and questionnaires does not always apply to the analysis of language. You should approach the statistics with a healthy skepticism; the way that you interpret such stats should always be supplemented by item-level statistics as well.
The top results table also provides category-levels means and standard deviations, which indicate the relative frequency/distribution of concept(s) of interest within the dataset that you have analyzed. If the mean of a dictionary is low (e.g., 0.01%), this means that the construct that you are trying to measure is quite rare (or, at least, that the words you are using to capture the construct are quite rare). This is typically true of specialized topics which are used only in specific texts but not otherwise.
The second table provides word-level means and standard deviations. These values are extremely useful in identifying the most frequently used words within each category. For instance, in the example below, "learn" was the most-used word in the "school" category. In many instances, you may realize that a very few specific words are driving the dictionary’s mean, while most other words are not used. You could modify the dictionary as needed and re-evaluate the internal consistency and word means.
PROTIP: Given the statistical properties of language, it is well-understood that often, a few words are going to be the largest contributors to any particular dictionary category. Word-level means can be extremely helpful in understanding what your dictionary category is actually capturing/reflecting about people's psychology. Additionally, these insights can be further bolstered by using LIWC-22's Contextualizer.
Benchmark Datasets
When it comes to benchmarking your dictionary and assessing its psychometric properties, it is reasonable to ask "What dataset should I use?" This is a surprisingly complex question, and the answer is seldom straight-forward. You can certainly assess the internal consistency of your dictionary on the dataset that you intend to apply the dictionary to later — this is perhaps the most straight-forward way to determine whether your dictionary has adequate internal consistency on the data where it counts the most. Indeed, this is similar to calculating Cronbach's alpha on questionnaire data: you are effectively taking the already-collected data and evaluating your measure's properties.
However, it is also the case that if you are tailoring your dictionary to perform well on your existing dataset, you can run the risk of "overfitting" your dictionary to a particular context or sample. Often, we instead might want to look to another dataset (or multiple datasets) to benchmark our dictionary and ensure that it is robust and not overfit to a single context.
If we're looking to evaluate our dictionary on an out-of-sample dataset, which one should we use? There is no objectively correct answer here but, as a general rule, you will want to find some data that has similar properties to the context(s) in which you imagine your dictionary will be used. For example, are your texts formal or informal? Are they SMS, e-mails, poems, etc.? Or, if you want to evaluate your dictionary irrespective of context, you might need to evaluate its psychometric properties across several datasets.
Today, language data is more accessible than ever before. There are a number of available datasets that you can use as a starting point for benchmarking your data (e.g., existing corpora of social media posts, speeches, books, etc.). We also encourage you to be creative: it's a really big world out there, and you may have to get creative when it comes to creating/curating a dataset of language data that best reflects the type of data for which you believe your dictionary to be well-suited.
Add Dictionary Words
Often, you will find yourself wanting some help in coming up with words to include in your dictionary — trust us, we know how much work it can be to create a dictionary from nothing. In the Add Dictionary Words tab, you can type in a list of words that you believe best represent the concept or category that you are trying to capture. LIWC-22 will automatically generate words that are most similar in meaning to the list of words you typed in. You can then easily go through the list of words generated by LIWC-22 and select the words you would like to add to your dictionary.
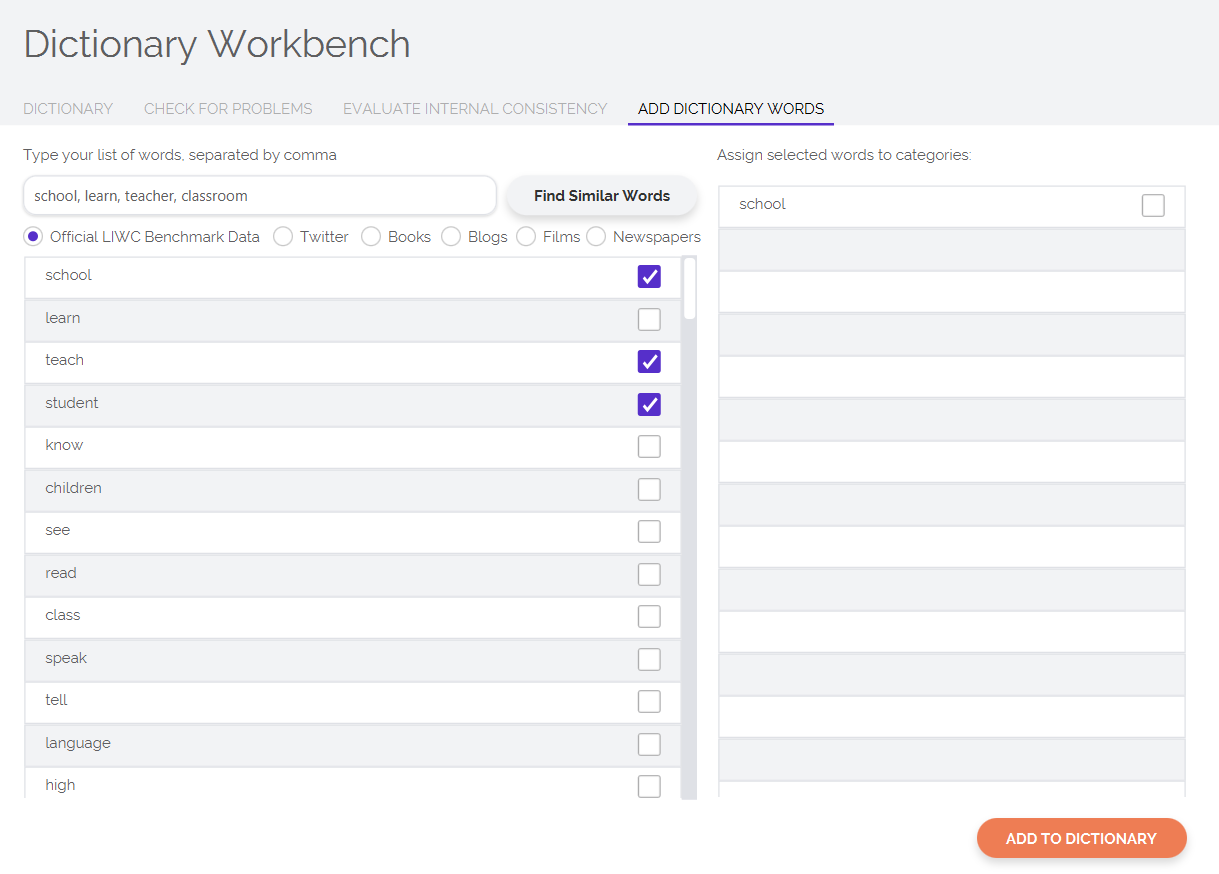
Note that LIWC-22's automatic word generation feature is built atop models that are pre-trained using a large, diverse set of language corpora, including social media, public domain books, and even LIWC’s own benchmark dataset. We currently have plans to add additional domain-specific models (e.g., social media, newspaper articles, etc.).
References and Further Reading
- Kennedy, B., Ashokkumar, A., Boyd, R. L., & Dehghani, M. (2022). Text analysis for Psychology: Methods, principles, and practices. In M. Dehghani & R. L. Boyd (Eds.), The handbook of language analysis in psychology. Guilford Press.
Additional Resources
It is often a good idea to use a large, varied collection of texts when evaluating the psychometric properties of your dictionary files. For users who do not have immediate access to their own corpora, we provide here for a demo dataset that you are free to download for learning/exploratory purposes. Please examine the README and LICENSE files before using this dataset — failure to do so may lead to embarassment should you find yourself at a dinner party that is well-attended by psychometricians.
Download the LIWC-22 demo dataset from here: liwc-22-demo-data.zip.